This is a simple website that compiles all of my data science research and projects
Check out my github and linkedin
I am a data scientist with three years of experience in econometrics, market analytics, engineering data processing, consumer analysis, and public policy analysis. I spend a lot of my free time thinking about how data science & statistics allows us to ponder otherwise unanswerable questions and am always trying to keep up with machine learning research.
Blood Donation Simulation

[Addendum material]
I donate blood frequently and I noticed that the Red Cross seems to always be announcing new blood shortages. There simply aren’t enough donors to make up for the demand for transfusions. There is, however, a group of people that are generally excluded from donating blood: gay men. This is a policy made in the 1980’s during the AIDS crisis, but new HIV testing technology should mean that allowing gay men to donate won’t put anyone at risk of infection. I made an agent based simulation of US blood examining the effects of allowing gay men to donate blood unimpeded. There is a small uptick in HIV transmissions per 100,000, but the amount of new blood available makes up for that in spades.
Note: I actually used information about generation 4 HIV tests for this simulation. Newer generation 5 tests would reduce the HIV transmission rate even more.
Measuring Urban Greenery
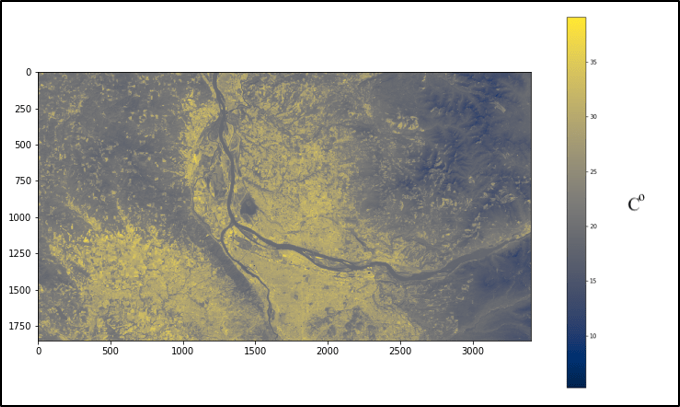
This is my published research on a novel methodology of measuring urban greenery with data going back to the 1980’s. My co-author and I measured the intensity of the urban heat island effect in Portland Oregon and used it as a proxy for the amount of urban deforestation occuring for the last couple decades. There was a huge debate Portland about how many trees were being cut down to make way for construction, and, as far as I can tell, we were the first to quantitatively measure it.
Spoilers: Portland has been really good about keeping it’s green spaces, and other cities can learn from its example.
Trump Twitter Research
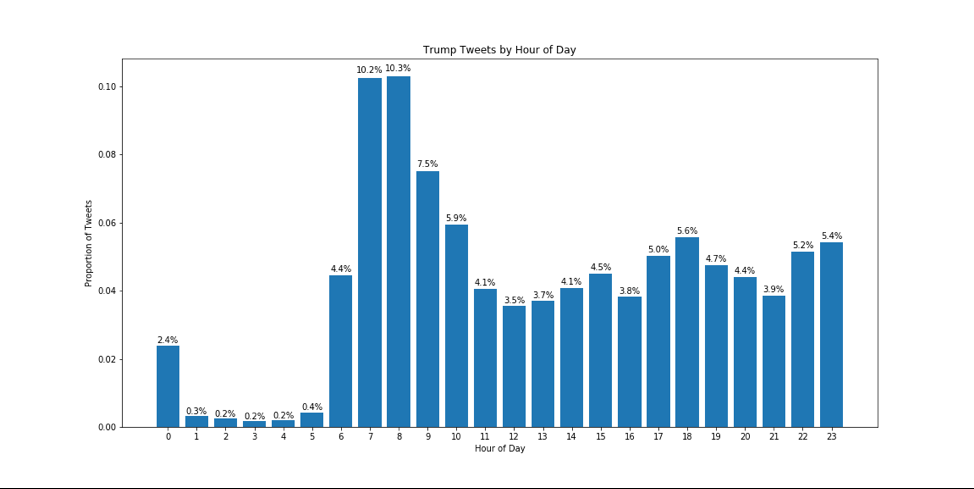
[twitter account]
I gathered all of Donald Trump’s tweets and created NLP features to determine if a given tweet will be followed up in the next couple of minutes. A gradient-boosted classifier then predict whether a given @realDonalTrump tweet will be followed up with another within 20 minutes. This project took months of research and effort to develop a good enough model to share with the world. Check out the medium article I wrote (linked above).
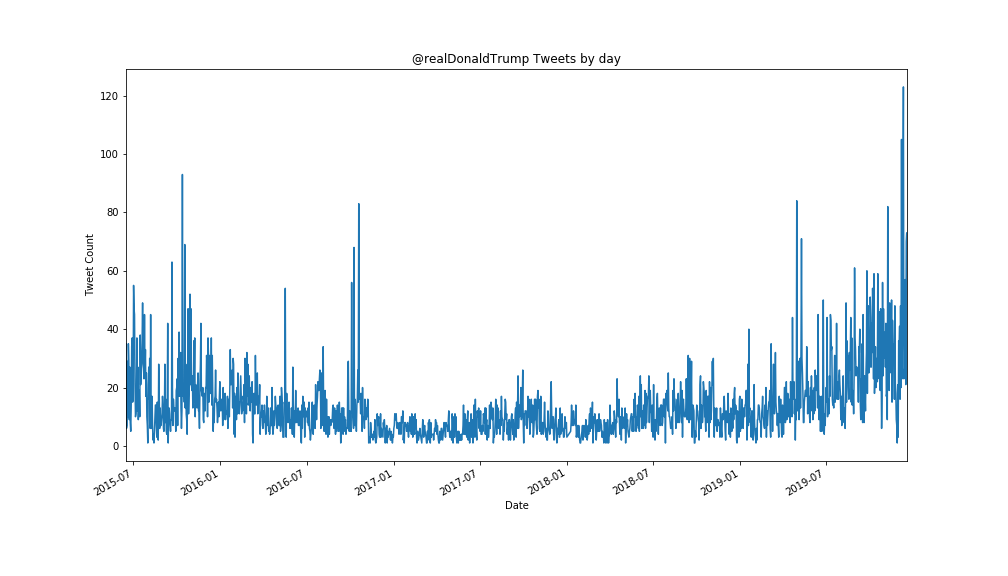
This is the only research I have which is not public. I bet every week on Predictit.org on how many time Trump will tweet on a given day and have been compiling data on what causes the president to tweet. His tweets are highly chaotic and heavily impacted by the number of times he’s mentioned on twitter, news, and his schedule. Normal time series forecasting (ARIMA, Holt-Winter, and even LSTM’s) is pretty lackluster and so I interpret his tweets through the lens of the fractal market hypothesis (read “The Misbehavior of Markets” by Mandelbrot for more information on this theory)
robby.gottesman@gmail.com
